
BAGEL-Unified-Multimodal-Pretraining
BAGEL: Emerging Properties in Unified Multimodal Pretraining
作者:Chaorui Deng, Deyao Zhu, Kunchang Li 等 (ByteDance Seed)
研究背景
统一多模态理解与生成(Unified Multimodal Understanding and Generation)是当前AI领域的热点方向。GPT-4o、Gemini 2.0等闭源系统展现了强大能力,但开源模型与之仍存在显著差距。现有开源统一模型主要在图文配对数据上训练,缺乏对复杂多模态交错数据(Interleaved Data)的利用。
研究目标
- 缩小开源统一多模态模型与闭源系统(GPT-4o、Gemini 2.0)之间的性能差距
- 解决现有模型架构中理解与生成模块之间的信息瓶颈(Bottleneck)问题
- 构建能够支持复杂多模态推理的大规模交错数据
核心概念
理解与生成之间的瓶颈(Bottleneck)
在采用 External Diffuser 架构的模型中,LLM/VLM 与扩散模型通过轻量级适配器连接:
- 语言模型生成少量潜在token作为”语义条件”
- 这些token被传递给扩散模块生成图像
- 问题:LLM的丰富上下文被压缩到少量token中,导致信息损失,尤其影响长上下文多模态推理
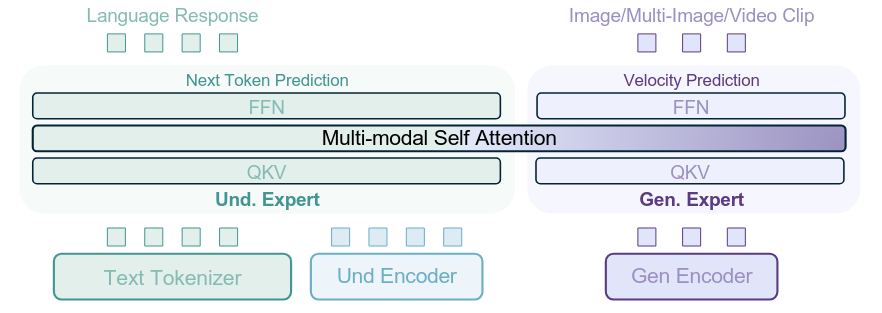
Mixture-of-Transformer-Experts (MoT)
与传统MoE不同,MoT复制整个Transformer层而非仅FFN:
- 理解专家:处理文本和ViT token
- 生成专家:处理VAE token
- 两个专家通过共享自注意力在每层交互
研究方法
架构设计
BAGEL采用无瓶颈的集成Transformer方案:
双视觉编码器:
- 理解编码器:SigLIP2-so400m/14,捕获语义信息
- 生成编码器:FLUX VAE,处理像素级信息
训练范式
| 模态 | 方法 | 损失函数 |
|---|---|---|
| 文本 | Next-Token-Prediction | Cross-Entropy |
| 视觉 | Rectified Flow | MSE |
损失权重比:$\text{CE} : \text{MSE} = 0.25 : 1$
广义因果注意力(Generalized Causal Attention)
对于交错多图像生成:
- Noised VAE tokens:用于Rectified-Flow训练
- Clean VAE tokens:作为后续生成的条件
- ViT tokens:统一输入格式,提升交错生成质量
采用Diffusion Forcing策略,对不同图像添加独立噪声级别。
数据构���
数据规模
| 数据类型 | 数据量 | Token数 |
|---|---|---|
| 纯文本 | 400M | 0.4T |
| 图文配对(理解) | 500M | 0.5T |
| 图文配对(生成) | 1600M | 2.6T |
| 交错理解数据 | 100M | 0.5T |
| 交错生成数据(视频) | 45M | 0.7T |
| 交错生成数据(网页) | 20M | 0.4T |
交错数据构建流程
视频数据:
- 视频预处理(分割、裁剪、质量过滤)
- 使用蒸馏的小型VLM生成帧间描述
- 构建时序对齐的交错序列
网页数据:
- 两阶段主题筛选(LLM + fastText)
- 质量过滤(分辨率、清晰度、相关性)
- Caption-first策略:为每张图像生成描述并插入其前
推理增强数据(Reasoning-Augmented Data)
受DeepSeek-R1启发,构建50万条推理增强样本:
- Text-to-Image生成
- 自由形式图像操作
- 概念性编辑
主要发现
涌现能力(Emerging Properties)
论文定义:某能力在早期训练阶段不存在,但在后期训练中出现
不同能力的涌现时间点(达到85%峰值性能所需token数):
| 能力 | 涌现时间点 |
|---|---|
| 多模态理解 | ~0.18T tokens |
| 图像生成 | ~0.68T tokens |
| 图像编辑 | ~2.64T tokens |
| 智能编辑(复杂推理) | ~3.61T tokens |
关键发现:
- 理解和生成能力最先收敛
- 编辑能力随后涌现
- 需要复杂推理的智能编辑能力最后涌现
- ViT tokens对智能编辑至关重要(移除后性能下降16%)
架构对比实验
在1.5B模型上对比Dense、MoE、MoT三种架构:
- MoT在生成任务上优势最明显
- 表明理解和生成可能需要不同的参数空间
实验结果
多模态理解(7B参数)
| 基准 | BAGEL | Janus-Pro | Qwen2.5-VL |
|---|---|---|---|
| MMMU | 58.6 | 41.8 | 49.3 |
| MM-Vet | 73.1 | 55.9 | 62.8 |
| MathVista | 69.3 | 54.7 | 68.2 |
| MMVP | 67.2 | 48.3 | - |
图像生成(GenEval)
| 模型 | Overall |
|---|---|
| BAGEL (w/ rewriter) | 0.88 |
| BAGEL | 0.82 |
| Janus-Pro | 0.80 |
| FLUX.1-dev | 0.82 |
| SD3-Medium | 0.74 |
智能编辑(IntelligentBench)
| 模型 | Score |
|---|---|
| GPT-4o | 78.9 |
| BAGEL w/ Self-CoT | 55.3 |
| BAGEL | 44.9 |
| Gemini 2.0 | 57.6 |
| Step1X-Edit | 14.9 |
讨论
优势
- 无瓶颈架构:理解与生成模块间无损信息交互
- 涌现能力:首次系统揭示统一多模态预训练的涌现规律
- 开源贡献:发布代码、模型权重和数据构建协议
- 推理增强:CoT显著提升复杂任务表现(WISE: +0.18, IntelligentBench: +10.4)
局限性
- 与GPT-4o在智能编辑上仍有差距(55.3 vs 78.9)
- 模型规模相对较小(7B active / 14B total)
- 训练计算成本高(需要大规模交错数据)
相关工作
统一多模态模型:
- Janus-Pro:采用离散视觉tokenizer的自回归方法
- MetaQuery-XL:冻结预训练VLM backbone
- Transfusion:统一AR和扩散的早期探索
视觉生成:
- FLUX.1-dev:当前SOTA扩散模型
- SD3-Medium:Stable Diffusion系列
未来方向
- 更大规模训练:探索更大模型和更多数据下的涌现行为
- 视频生成:论文展示了初步的视频生成能力,有待深入
- 强化学习:无瓶颈架构为多模态RL提供了基础
- 世界建模:导航、3D操作等世界建模任务的进一步探索
参考文献
- Deng et al. (2025). Emerging Properties in Unified Multimodal Pretraining. arXiv:2505.14683
- DeepSeek-AI (2025). DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
- Esser et al. (2024). Scaling Rectified Flow Transformers for High-Resolution Image Synthesis (SD3)
BAGEL-Unified-Multimodal-Pretraining
http://chen-yulin.github.io/2026/02/06/[OBS]Deep Learning-BAGEL-Unified-Multimodal-Pretraining/

